
人们往往会高估未来一年内能完成的目标,而又往往会低估未来十年能做到的事情。本期墨子沙龙邀请陆朝阳教授为客串编辑,构思了一个脑洞大开的提问:“如何实现一百万个量子比特的纠缠和量子计算”,并邀请了正在三个不同物理体系(光子、超冷原子、超导线路)从事研究的几位青年研究人员一起讨论和回答。
目前,科学家们基于各种不同的物理体系和不同的途径开展了量子计算的研究。在进入正题之前,先分享英国帝国理工学院Terry Rudolph 教授对此的一段叙述 [ 翻译自 APL Photonics 2, 030901 (2017) ]:
量子计算技术具有难以想象的巨大潜力,并且在通信、高精度测量以及其他还不可预见的领域中具有可以期待的相关衍生应用。目前,其大规模物理实现瓶颈的关键还在于研究者的创新能力和实验技术,而不是研究经费和资源的多少。正被严肃研究的每一种量子计算实现路线(基于不同的物理体系和途径)都有助于我们更深入理解所涉及系统的物理规律,同时也将工程的极限不断向前推进。作为一个科学共同体,我们现在拥有各种类型迥异的物理系统,在这些系统中,我们正努力实现对每个单独的基本组成单元的精微操控。不管采取哪种方案,我们都希望在不久的将来实现大规模量子纠缠,而纠缠正是所有量子奇异现象的精要所在。
人类已经历经了“第一次量子革命”,在这里,相比量子纠缠来说不那么奇异的量子现象(例如,离散能量、隧穿效应、叠加效应和玻色凝聚等)为人类催生了一系列新技术(例如,晶体管、电子显微镜和激光器等),这些技术作为主要推动力又继而推动了计算机、GPS和互联网等的发展,所有的政治家今天也可以看到它们每一项的价值是至少数十万亿美元级别的。正如第一代的各种量子技术需要在不同系统上实现一样,第二代量子技术也可能会走类似的路线。如果对于所有的第二代量子技术,仅仅一种物理系统就能实现所有功能,那将是非常令人惊奇的。历史已经证明,几乎所有偶然的科学发现都是在我们突破物理极限(如使材料比以往更低温、更纯净、更小等)的过程中涌现的。而这正是目前实验量子信息科学正在做的事情。
因此,对于大部分想有所作为的研究生来说,无论是从事量子通信、量子精密测量、还是量子模拟和计算,一定不要盲目追求时髦、轻信新闻媒体的宣传,重要的是把特定的物理体系的潜力发挥到极致(如下图)。

图片源于网络
下面进入正题。
回答:陈明城、丁星、顾雪梅、吴玉林
修订:陆朝阳
量子计算最近几年频繁出现于各种科技新闻报道。量子计算机凭借其强大的计算能力,将会给人类信息处理的方式带来颠覆性的改变。当然,美好的东西往往不是那么容易实现。事实上,量子计算的理论早在上个世纪80年代就有了,过去几十年里,大量的科学家一直致力于实现量子计算机,但直到今天我们还没有真正可用的量子计算。可见实现量子计算机是非常困难的。
作为一个超导量子计算研究的从业者,在这里简单回答一下制备一台超导量子计算机主要有哪些挑战。
去年,谷歌利用超导量子计算机首次在实验上证实了量子计算机具有远远超过超级经典计算机的计算能力,展示了“量子优越性”(见下图)。这是一个划时代的实验,要知道,以前量子计算机的超强计算能力仅仅是理论上的估计,从未被实验证实过,在实际中是否真正可行是一直存在质疑的。从此以后,量子计算机具备超强计算能力成为确切无疑的事情。

然而,我们离制造出一台有实用价值的量子计算机还非常遥远。量子称霸实验仅仅是通过一个特殊设计的算法,证实了量子计算机具备超强计算能力,但这个算法是没有任何实用价值的。按照现在的估计,一台能求解有实用价值问题的超导量子计算机,需要有上百万个量子比特,而现在规模最大的超导量子计算机仅仅包含53个量子比特。可见我们离实用量子计算机还有多遥远。
为什么需要上百万个比特呢?那是因为量子计算理论上所说的比特,是指完美的、不会发生任何错误的比特,专业上叫作“逻辑比特”。然而现实中的东西总是不完美的,超导量子计算机中的量子比特也是这样。我们把实际量子计算机中的量子比特叫做“物理比特”。对一个物理比特进行操作,结果会有一定概率出错。会出错倒也没什么,现实中大部分事情都这样,只要出错率低于能够容忍的阈值就可以了。
对量子计算机,麻烦在于,要想求解有实用价值的问题,这个能容忍的阈值实在太低,大概在百万分之一。这个阈值低到有多恐怖呢,拿超导量子比特来说,对它的操控是通过10纳秒级微波脉冲实现的,这意味着要在一亿分之一秒的时间内,实现百万分之一精度的控制!大家知道,快的东西一般不准,准的东西很难快,而直接实现理想量子比特却要求同时做到极致快和极致准,这远远超出了人类科技所能达到的高度。量子计算机只能另寻解决方案:量子纠错。这就是我们为什么需要上百万个物理比特的原因。
做到一百万个量子比特有多难?我们可以看看超导量子计算的发展史:2000年左右,第一个超导量子比特研制成功;然后经过15年左右的发展,2014年左右,超导量子计算处理器做到了10比特水平;又经过近5年的发展,到2019年,超导量子计算处理器做到了50比特水平。从这可以看出,要做到一百万个比特是极具挑战的事情,超导量子计算的发展还在很初步的阶段,还有很长的路要走。
面临的挑战首先是量子比特的实现本身就是非常具有挑战性的技术。要实现量子计算,重要的不仅仅是比特的数量,比特的质量更关键。而前面说到的量子纠错是质量不够,数量来凑并。这个说法其实并不准确,严格来说,要实现量子纠错,物理比特的错误率必须低于某个阈值。
量子比特能达到的操控精度由比特本身的性能、测量系统的水平、量子调控的水平三方面共同决定。这三方面每一项的提升都是一个系统工程。超导量子计算发展到今天,依赖的技术大多是现有的成熟技术。这主要是因为超导量子处理器的规模还不是很大,从设计、制备、测试到操控,都可以直接用商用的仪器设备或经过简单的改造来实现,和常规的科学研究课题没本质区别,可以完全按照基础科研的模式开展研究。

图片来自 Annual Reviews of Condensed Matter Physics 11, 369-395 (2020)
当超导量子处理器规模达到几十个比特甚至更大以后,大部分商用仪器已经无法满足需求,甚至现有技术都无法满足需求,需要系统性地从头开发整套的仪器设备和技术,这包括:
一、超导量子芯片设计、仿真软件,类似于半导体芯片领域的EDA软件。超导量子计算机的核心部件是超导量子处理器芯片,和半导体集成电路芯片一样,规模大了以后纯靠人手工无法完成设计、仿真,需要EDA软件辅助设计和仿真。超导量子处理器芯片基于独特的超导约瑟夫森结这种非线性器件,基本组成单元是量子器件而不是传统电子学元件。和半导体芯片电路特性完全不同,其电路原理和结构设计遵循完全不同的逻辑,不可能直接使用现有的半导体芯片设计EDA软件,需要重新开发;
二、大规模超导量子芯片制备产线,类似于半导体芯片制备产线。超导量子处理器芯片基于超导材料,对制备和工艺有特殊要求,这意味着芯片制备需要专门的工艺和设备产线;
三、超导电子学技术和低温电子学技术。当芯片集成比特数达到数千个以后,按照现有的模式,用室温电子学控制设备控制每一个比特几乎不可能实现,需要将比特的控制部分和量子芯片集成,能够达到这个目标的唯一技术是超导电子学。目前超导电子学技术还处在非常基础的阶段,实际应用非常少,如何与量子芯片集成更是有待研究的全新课题;
四、大功率极低温制冷机。超导量子处理器只能在10mK左右的极低温(约零下273.14度)下才能工作,而且还要求提供足够的制冷功率,目前能做到的只有稀释制冷机。当前的稀释制冷机技术仅能做到满足数百个比特的需求,支持更大规模的量子芯片的技术仍是一个待研究的课题。

当然,如果一百万个量子比特最终被证实在实际中是很难实现的,实用量子计算也不是完全没有希望。我们通常所说的实用量子计算需要百万级别的量子比特,是基于已知的量子算法和现有的比特操控错误率,但不管是量子算法还是比特操控错误率,将来都有可能出现新的突破。一方面,制备工艺、量子调控技术的提升会让物理比特的出错率降低,大大降低实际需要的物理比特数,另一方面将来有可能提出全新的实用量子算法,对量子比特出错阈值有更低的要求,也会大大降低实际需要的物理比特数量。这两方的突破很有可能在不久的将来,在人类实现通用量子计算这个遥远目标前,为量子计算带来一些近期的有价值应用,量子人工智能就是其中的一种可能。
光子可以较容易地展示出量子态的叠加性,具有简单的单量子比特操控方法。通常一个可见光区域的光子能量是几百THz,是其他类型量子比特的百万倍以上,远远大于各种热噪声,因此避免了使用昂贵的稀释制冷机。
光子清高孤傲,特立独行,母胎单身一万年,从不和其他光子搭讪,能够在较长时间内携带并保持量子信息。其中一个很好的例子就是Lyman-alpha blob 1 (简称LAB-1)发出的光在旅行了115亿年后到达地球时仍保持原始的极化状态(母胎单身)。此外,最显然的,要说谁跑得快(对应信息传输和处理速度),恐怕目前没谁敢和光比。
光一直站在人类解释大自然奥妙的前沿。量子信息领域也不例外,量子信息实验领域第一个真正的突破——1997年的第一个量子隐形传态实验,就是通过操纵多光子来实现的。到去年,实验室里面实现了20个单光子、数百个分束器的玻色取样,输出态空间维数达到了370万亿。在产业界,总投资数亿美元、位于硅谷的初创公司PsiQuantum和位于加拿大的Xanadu,都号称在致力于建造一台商用的光量子计算机。PsiQuantum声称,5-10年内他们的设备将包含100万量子比特。

积跬步,以致千里:要盖一栋由一百万个光量子比特组成的高楼大厦,首先要把每一个砖头——理想的量子光源——造好。单光子源,顾名思义是每次只发出一个光子的光源,但要想单光子源可以应用于量子计算,还需要同时满足确定性偏振、高纯度、高全同性和高效率这四个几乎相互矛盾的严苛条件。2000年,美国加州大学研究组在量子点体系观测到单光子反聚束。2002年,斯坦福大学研究组观测到双光子干涉。2013年,中国科大研究组在国际上首创量子点脉冲共振激发技术,只需要纳瓦的激发功率即可确定地产生99.5%品质的单光子;2016年,研究组研制了微腔精确耦合的单量子点器件,产生了当时国际最高效率的全同单光子源;2019年,研究组提出椭圆微腔耦合理论方案,在实验上同时解决了单光子源所存在的混合偏振和激光背景散射这两个最后的难题,成功研制出了确定性偏振、高纯度、高全同性和高效率的单光子源。
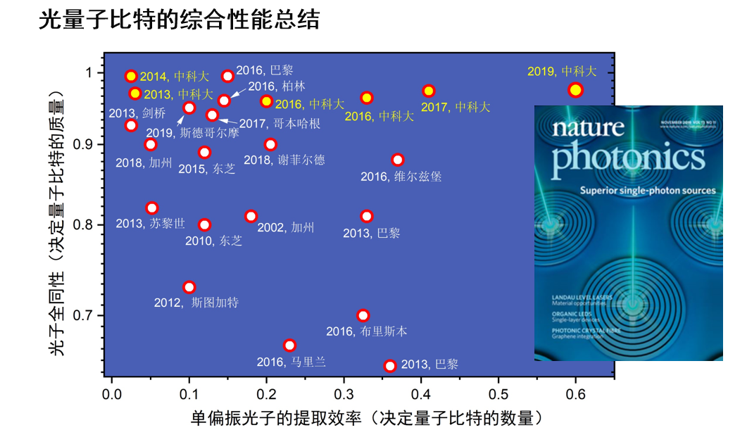
基于量子点的单光子源的两个核心指标的综合性能国际发展总结
目前单光子的单偏振提取效率还只有~60%,因此需要进一步设计更好、更鲁棒性的微腔结构(正在进展中),将单偏振提取效率不断提升到接近100%。假设有一天我们有了每个指标都超过99%的单光子源,那又该如何进行线性光学量子计算呢?
这里将量子计算简单的分类为非通用量子计算和通用量子计算。对于非通用量子计算,不需要纠错,只完成特定的量子计算任务,可以用于演示“量子优越性”(低调)或“量子称霸”(高调)。在线性光学体系中最有希望实现量子优越性的模型之一是玻色采样。这个模型只需要几十个全同的单光子输入到一个高维线性光学网络,并在出口获得可能的多光子符合事例即可。
对于通用量子计算,还需要在独立单光子之间实现控制逻辑操作。然而,光子之间的相互作用非常弱,这一光子在量子通信中的优点在量子计算中成为了一个弱点。可是,这并难不倒聪明绝顶的物理学家们,他们先后提出了KLM方案、腔电动力学CNOT方案,以及基于簇态的单向量子计算方案。后者是目前PsiQuantum公司正在推的,把CNOT的难点转移到了制备足够大尺度的纠缠态上,在此基础上,就只需要测量了。

图片来自APL Photonics 2, 030901 (2017)
那怎么从单光子或者纠缠光子对制备一百万光子的纠缠态呢?这个问题问得好!鲁迅先生曾经(然而并没有)说过:太极生两仪,两仪生四象,四象生八卦……在这一指导思想下,在多光子纠缠方面,中国科大研究组在过去几年从4光子纠缠实现了12光子的纠缠,并演示了20光子的玻色取样。此外,量子点也可以直接产生两光子纠缠以及多光子簇态纠缠。随着光子系统效率和全同性的进一步提升,以及近期高斯玻色取样新方案的出现,有望解决效率的扩展问题,爬升速度有望大大加快,说不定2020年底就做到了接近100个光子呢?
由于量子系统不可避免的退相干效应,量子态和环境的耦合会受到各种噪声的影响,因此导致计算过程中产生错误。如果不纠正这些错误,那么经过一系列计算后,量子计算机将输出被随机噪声破坏的数据。为了保证大规模量子计算后只存在较低的错误率,普适的容错量子计算要求一个包含有很多量子比特的三维簇态,其中两维被映射到空间上,另一个维度被映射到时间上。这种特殊的三维结构,不需要所有的光子都同时处于相互作用状态,而只需要对邻近的纠缠态之间进行作用,从而允许构建稳定的子簇态。为了获得更多量子比特的簇态,我们只需要按照标准簇态的计算方法遍历编码单个量子比特的路径,分布式拼接已有的纠缠态,最终实现大尺寸的簇态。我们也可以将其理解为随时间演化的表面编码,每一层的局域操作将编码的结果传输到下一层的编码面上。这些编码的边界支持多个编码的量子比特,因而编码的量子门随着时间演化的边界条件得以实现,并且噪声的影响可以通过系统编码的拓扑性质来降低。
其实,说一千道一万,对物理学家来说,量子计算研究的终极灵魂拷问是:
“When will quantum computers do science, rather than be science?”
不管名字叫做量子计算机还是量子模拟机,我们的目标就是造出一个利用量子力学原理运行的新机器,它能成为物理学家、化学家和工程师在材料应用和药物设计方面的重要工具,应用于模拟复杂物理系统,量子化学,指导新材料设计,解决高温超导等物理问题,在特定模拟问题的求解能力上全面碾压经典的超级计算机。针对这一目标,包括诺贝尔物理学奖获得者杨振宁、Anthony Leggett在内的众多重要量子物理学家都认为,超冷原子由于其纯净的环境、各种丰富的相互作用、几十年来积累的各种精致的控制手段,有望在不久的将来在非平庸的量子模拟方面取得重大突破。
如何实现一百万个量子比特的纠缠是一个有趣的问题!物理学家最善于把复杂的问题简单化,像那个“如何把一只大象放进冰箱”的经典问题,让我们分三步考虑: (1)放一个量子比特;(2)放100万个量子比特;(3)添加上量子纠缠。
一、100万个量子比特:单原子阵列
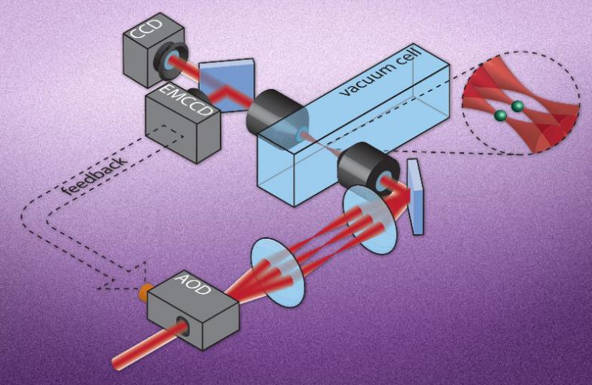
我们预计最简单最自然的量子比特是一个单原子(左图),搞定第一步。100万个量子比特,刚好是100*100*100的3维阵列。假设临近原子之间的距离是10微米,100万个量子比特正好是边长1毫米的立方体(右图),搞定第二步。

我们具体看下怎么做出这样的原子立方呢?我们可以利用超冷原子光晶格产生的激光驻波,一个一个地囚禁单原子,一个萝卜一个坑规规矩矩地做成固定间隔的立方体形状。或者,以光镊作为定位工具,任性地把原子一个一个的排列成我们任意想要的间距和形状,比如3维的埃菲尔铁塔、莫比乌斯环、碳60,而且还可以实时动态变化(像南归的大雁那样,一会儿排成N形,一会儿排成B形),排出立方体更不在话下。

图片来自Nature 561, 79–82 (2018)
二、让100万个量子比特纠缠:激光操控原子
前面两步我们有了100万个量子比特来存储量子态,接下来就是第三步,通过原子相互作用产生量子纠缠。

用激光脉冲来控制原子是最方便的。相比于超导量子电路或者半导体量子点等固态系统中,100万个量子比特需要放置几百万根控制线【超导量子计算男神John Martinis曾经介(tu)绍(cao)他的大部分工作就是在解决如何布线这样的繁琐技术问题(见上图)】,单束激光可以通过动态编程,定向和聚焦于任意一个或一批原子上,对任意原子进行可控的量子操纵(下图)。例如,通过激光激发原子到里德堡态,可以把单原子间的相互作用打开,达到超过10个数量级的开关比。原则上,第三步产生纠缠可以很简单:一个基本的事实是,一个随机的量子态是最大纠缠态,因此只需要让原子进行充分的随机相互作用就行。
图片来自https://news.mit.edu/2016/scientists-set-traps-atoms-single-particle-precision-1103
让我们增大一点难度,来产生簇态纠缠,这种纠缠结构可以用来实现通用的量子计算。近期,中国科大科研人员在光晶格中取得重要进展,研究人员通过确定性制备超冷原子阵列和高精度量子门实现了1250对原子纠缠,是通往制备簇态纠缠的重要一步(欲知更多详情猛戳墨子沙龙漫画深度解读 “为了让你更完美,我必须冷酷到底——极度深寒量子模拟” )。

图片来自http://quantum.ustc.edu.cn/web/node/852
三、可扩展的量子纠缠:量子纠错
假设一个量子操纵的可靠度是99.99%,那100万个量子比特都各操纵一下,整体的可靠性就是0.9999^1000000≈10^(-44),操纵就失败了。这是大规模量子纠缠和量子计算面临的最大挑战。解决这个问题的方法是对量子操纵进行纠错,让大规模量子操纵的错误不要持续累积。
不过量子纠错很消耗资源,比如用100亿个高品质的物理量子比特来实现可容错的100万个逻辑量子比特。按照我们前面的排法,100亿个单原子量子比特阵列差不多是边长2.2厘米的立方体阵列,大小还是很迷你的。

容错量子计算有个基本的门槛,量子操纵的可靠性需要大于某个阈值。目前,利用光镊控制的单原子量子比特可以实现大于99.7%保真度的初始化,大于99.6%保真度的单比特操纵,大于99.9%保真度的非破坏读取,通过里德堡态相互作用可以实现大于99.5%保真度的双比特纠缠门,这些基础指标都达到了二维表面码容错量子计算的阈值的基本要求。

图片来自https://quantumarchitectureprinceton.github.io/
二维表面码容错量子计算是目前最吸引人的可扩展量子计算设计(上图)。它只需要在平面上排布局域相互作用的量子比特,因此非常适合比如超导量子比特等固态芯片体系。不过这个设计有个大缺点,它需要辅助超大规模的量子态蒸馏才能实现通用的容错量子门,因此非常消耗资源。三维的原子量子比特阵列提供了新的机会:比如三维拓扑码可以直接实现通用的容错量子门,极大地节约了可扩展量子计算的资源开销。
目前我们还很难预测未来哪个物理体系会率先实现100万个量子比特的高保真度纠缠。其中单原子阵列展示了潜在的竞争力:在高分辨显微镜头下,动态光镊排布三维原子构型,激光独立寻址和操控任意原子及其相互作用,三维容错编码机制高效地纠正量子错误,最终实现大规模量子计算。

图片来自网络
责任编辑:杨玉露)
(版权说明,转载自:墨子沙龙公众号)